记一次慢SQL引发的头脑风暴
背景
在一个阳光明媚的早晨,报警机器人邀我共进早餐:MySQL 集群 CPU 高涨,达到 70% 并持续了数十秒,我查看监控和日志,定位异常来源于下面这条 SQL :
1 | func Method(ctx context.Context, tenantId int64, excludeSpaceType []SpaceType) (int64, error) { |
1 | SELECT COUNT(*) FROM XXX |
分析
目标 SQL 是一个多条件的 COUNT 查询,先来看看包含条件字段的索引情况:
- 索引A:
KEY idx_tid_spaceid (tenant_id, space_id) - 索引B:
KEY idx_tid_scope_ctime (tenant_id, scope, create_time) - 索引C:
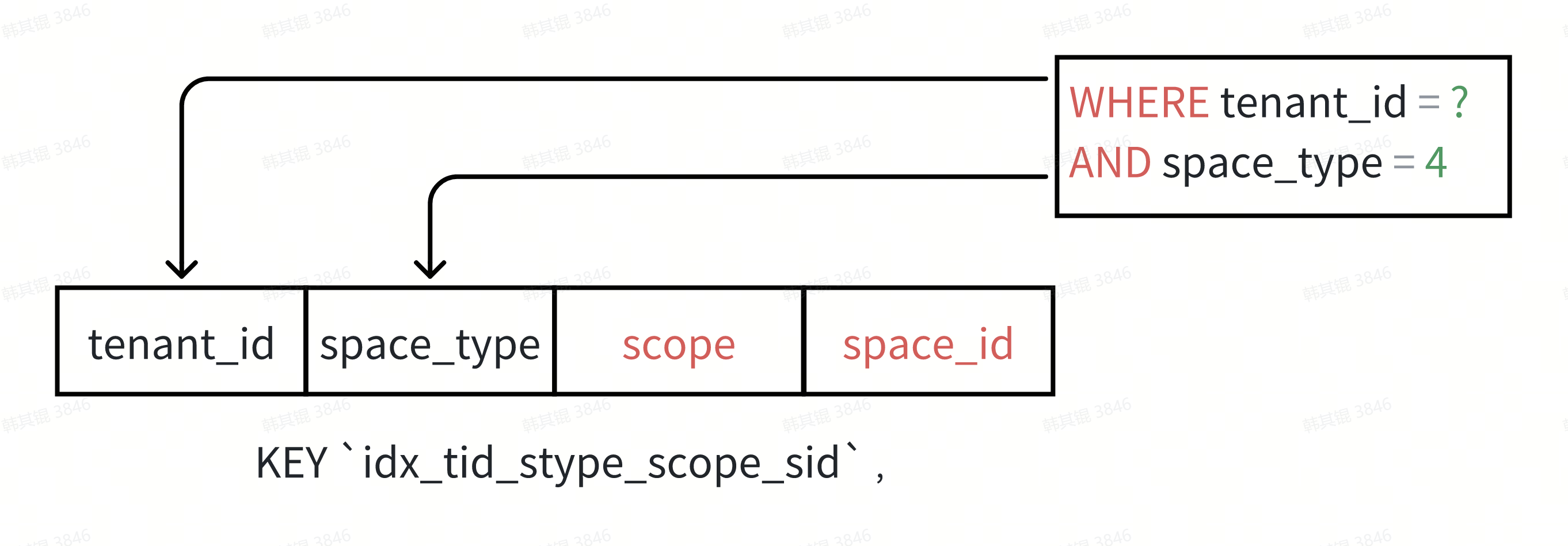
KEY idx_tid_stype_scope_sid (tenant_id, space_type, scope, space_id)
| 字段 | 条件 | 索引情况 | 是否利用索引 |
|---|---|---|---|
| tenant_id | = | 索引A、索引B、索引C | 是 |
| space_type | NOT IN | 索引C | 否 |
| space_version | = | - | 否 |
| delete_flag | =、OR | - | 否 |
| default_attr | != | - | 否 |
同时存在 !=、or、not in 条件,简直反索引拉满,索引利用率极低,查询大租户时内存筛选耗时巨大,因此执行超时。Explain 查看执行计划:
| 列名 | 列值 |
|---|---|
| key | idx_tid_spaceid |
| rows | ? |
| filtered | 1.2 |
| Extra | Using where |
初见端倪
SQL优化的手段很多,先看看能否提高索引覆盖率。可以发现覆盖条件中的字段是最多的是索引C(tenant_id, space_type, scope, space_id)。其中 tenant_id 可利用索引,而 space_type 由于使用了反范围查询的 NOT IN ,无法利用索引。分析代码发现 space_type 只有4种枚举类型,且传值固定,可以将传入过滤条件替换成等效的等值查询:
1 | -- 原条件: |
到此我们已经把能够使用索引的字段都用完了,但由于 space_type 的筛选度不高,扫描后内存筛选的压力还是很大,依然存在慢查询风险。那么,我们是否可以把数据返回给应用层进行筛选,再手动计数呢?
1 | SELECT space_version, delete_flag, default_attr FROM ? |
面露难色
不难发现,当数据量非常大时,这样的SQL是能否解决慢查询不说,反而会导致网络传送压力增大,还可能存在堆内存溢出的风险。基于此可以很容易想到,可以通过在应用层维护一个的游标,对数据进行分批查询,手动筛选计数:
1 | SELECT space_id,space_version, delete_flag, default_attr FROM ? |
当我准备基于这条 SQL 改造代码时,感觉怎么越看越不对劲,于是我又执行了一次 Explain ,结果令我黯然失色,SQL 改用了索引 uniq_space_id :
| 列名 | 列值 |
|---|---|
| key | uniq_space_id |
| rows | ? |
| filtered | 3.36 |
| Extra | Using index condition; Using where |
简单分析可以发现,为了保证 space_id 的顺序性,我使用 ORDER BY ,这种情况下优化器为了避免内存排序,认为直接使用 space_id 的索引顺序性效率更高。
- 大租户索引筛选度低,排序基数大,优化器优先使用索引:
uniq_space_id - 小租户索引筛选度高,排序基数小,优化器优先使用索引:
idx_tid_stype_scope_sid
虽然不会导致单条 SQL 超时了,而且优化器会基于情况选择索引,但这也导致了大租户扫描数据量反而增加,之前的条件无法利用到索引,过滤后只剩下 3.36% 的数据符合条件,返回应用层还要再过滤一遍,效率依然低下。
曙光初现
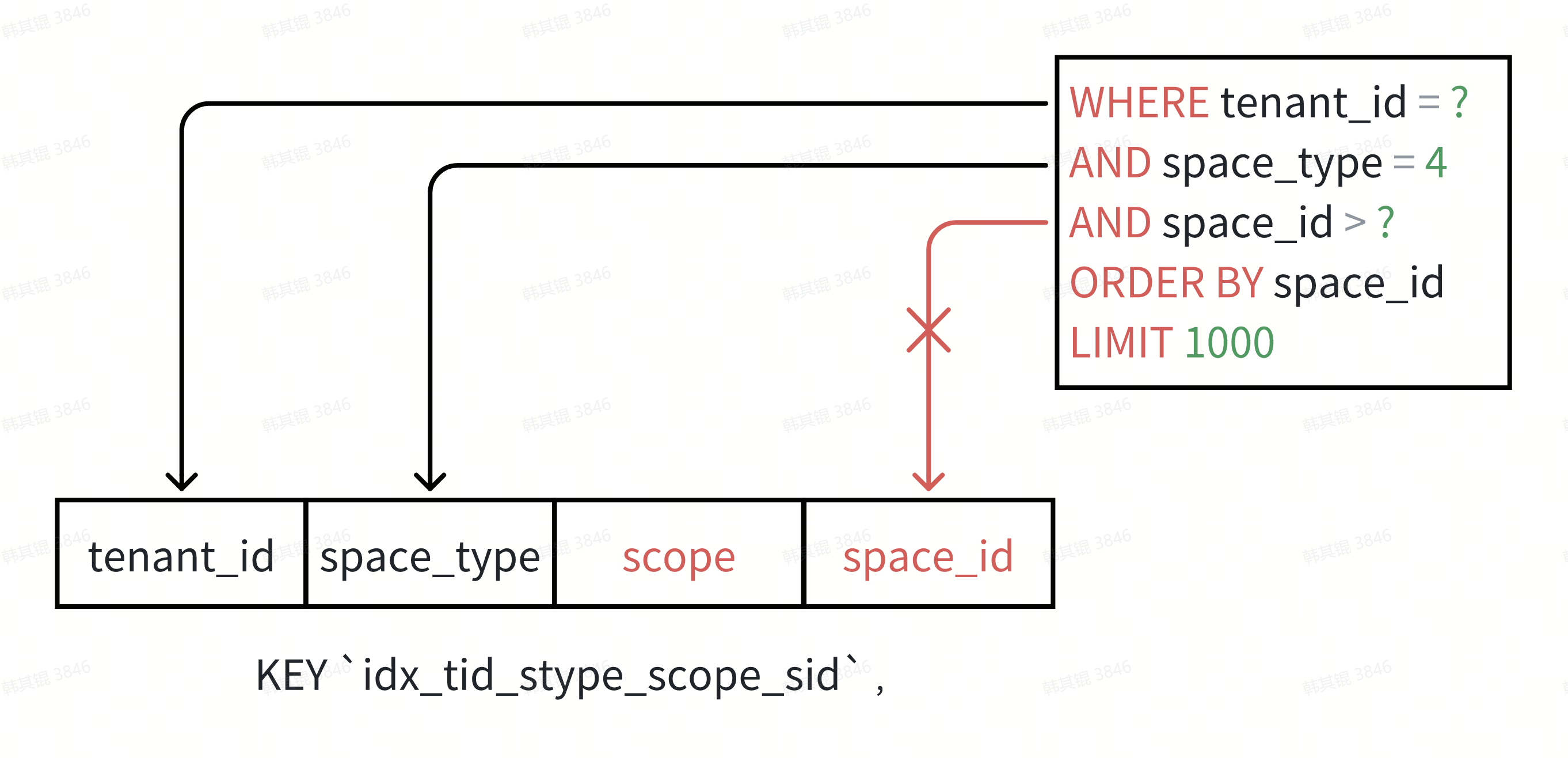
正当我一筹莫展的时候,注意到索引 idx_tid_stype_scope_sid 最后一个列恰好是 space_id ,但由跳过了 scope 条件,不符合索引原则,还是无法利用索引:
难道就没有更好的办法了吗?在查看了 scope 的枚举后,发现枚举的值较少,且不会随意扩展,那是不是意味着可以手动补齐 scope 字段?这样不仅完全利用到了索引,还可以并发执行多条 SQL ,在确认无事务风险后,最终的 SQL 变成了下面这样:
1 | SELECT space_id,space_version, delete_flag, default_attr FROM ? |
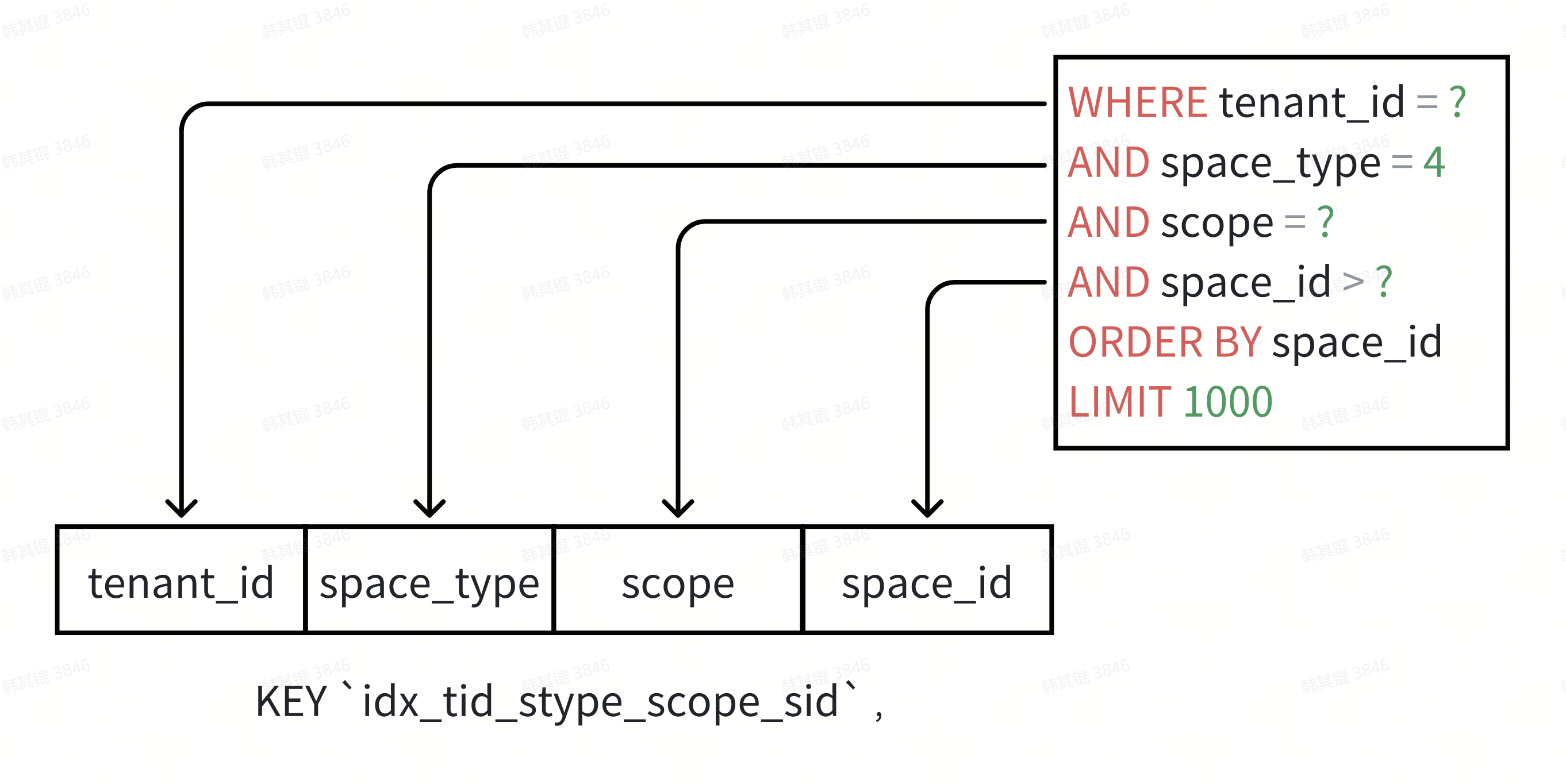
此时 SQL 已经完全利用了索引,并且可以使用多个协程并发执行提速,下面是优化后的代码:
1 | func Method(ctx context.Context, tenantId int64) (int64, error) { |
如果担心优化器乱搞事情,还可以强制指定索引:
1 | SELECT ... FROM ... |
总结
这次的问题 SQL 其实非常简单,但又非常经典,整个优化分析过程涉及了很多索引知识。SQL 的优化的方式很多,但都可以总结为:减少查询数据量,提升索引命中率,减少磁盘 I\O 次数。除了 SQL 本身的优化,本次也通过手动筛选计数,并发分页扫描的方式,利用应用层有效平衡了性能和内存占用。
分享本次案例对我们有何启发呢?我们无法预测系统数据量的爆炸增长,以至于现在看起来没毛病的 SQL ,在未来可能成为隐患。我们可以为了保证开发效率而不要求每个细节做到极致,但还是建议尽可能遵守设计原则,避免极端情况下的系统风险。